NVIDIA RTX�@��AI��������5�� �p�ɸ㶨��ģ��
20231117 ��Դ���Ӿ��` ���ߣ���С���`
�Ӿ��`��ȫ����Ч�����I��Q���N��X�ӆ��}

11��16����Ϣ�������e�е�ܛIginteȫ���g����ϣ�ܛ�l��һϵ��AI���P��ȫ����ģ�͡��_�l�����YԴ�������_�l�߸������ጷ�Ӳ�����ܣ���չAI������
���nj��ڮ�����AI�I��ռ���^��������λ��NVIDIA���f��ܛ�@��������һ�ݴ�Y�����oՓ������OpenAI Chat API��TensorRT-LLM���b�ӿڣ�߀��RTX�ӵ����ܸ��MDirectML for Llama 2���Լ��������T���Z��ģ��(LLM)����������NVIDIAӲ���ϫ@�ø��õļ��ٺ͑��á�
���У�TensorRT-LLM��һ�����ڼ���LLM�����Ď죬�ɴ������AI�������ܣ�߀�ڲ������֧��Խ��Խ����Z��ģ�ͣ�������߀���_Դ�ġ�
����10�·ݣ�NVIDIAҲ�l��������Windowsƽ�_��TensorRT-LLM�������RTX 30/40ϵ��GPU�@�����_ʽ�C���Pӛ���ϣ�ֻҪ�@�治����8GB���Ϳ��Ը��p�ɵ����Ҫ�������AI����ؓ�d��
�F�ڣ�Tensor RT-LLM for Windows����ͨ�^ȫ�µķ��b�ӿڣ��c OpenAI �V�ܚgӭ������ API ���ݣ���˿����ڱ���ֱ���\�и��N���P���ã�������Ҫ�B���ƶˣ��������� PC �ϱ���˽�˺͌��Д����������[˽й¶��
ֻҪ��ᘌ�TensorRT-LLM�����^�Ĵ��Z��ģ�ͣ��������c�@һ���b�ӿ����ʹ�ã�����Llama 2��Mistral��NV LLM���ȵȡ�
�����_�l�߁��f���o�跱���Ĵ��a�،�����ֲ��ֻ����һ���д��a���Ϳ���AI�����ڱ��ؿ��و��С�
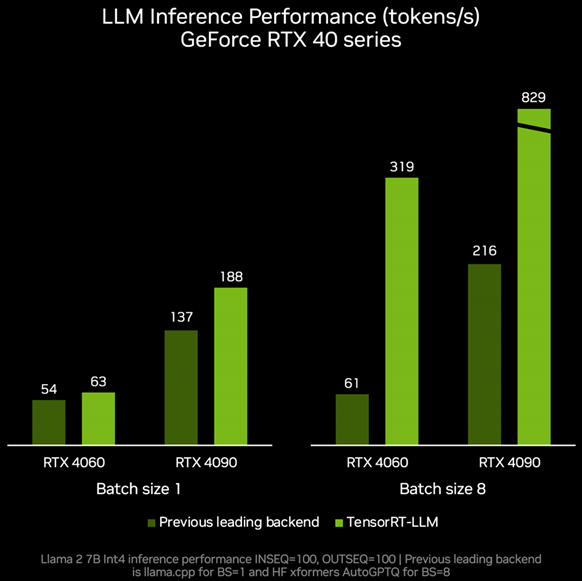
���µ�߀����TensorRT-LLM v0.6.0�汾���£�������RTX GPU�ώ�������_5��������������������֧�ָ������T�� LLM������ȫ�µ�70�|����Mistral��80�|����Nemotron-3���_ʽ�C�Pӛ��Ҳ���S�r�����١��ʴ_�ر����\��LLM��
�������y������RTX 4060�@������TenroRT-LLM���������ܿ����ܵ�ÿ��319 tokens�����������˵�ÿ��61 tokens��������4.2����
RTX 4090�t���ԏ�ÿ��tokens���ٵ�ÿ��829 tokens�����������_2.8����
���ڏ����Ӳ�����ܡ��S�����_�l���B���V韵đ��È�����NVIDIA RTX���ɞ鱾�ض˂�AI���ɻ�ȱ�ĵ������֣���Խ��Խ�S���ă�����ģ�ͺ��YԴ��Ҳ�ڼ���AI���ܡ��������σ|�_RTX PC�ϵ��ռ���
Ŀǰ�ѽ���400�����������l����֧��RTX GPU���ٵ�AI���á��Α��S��ģ�������ԵIJ�����ߣ����ŕ���Խ��Խ���AIGC���ܳ��F��Windows PCƽ�_�ϡ�
���݁��ԾW�j�������֙࣬Ոϵ�h��
�Ӿ��`�LJ���������I����X�ӹ���ܛ�������㰲ȫ����Ч��Q��X�ӆ��}
 �Wվ�䰸̖��
�Wվ�䰸̖��